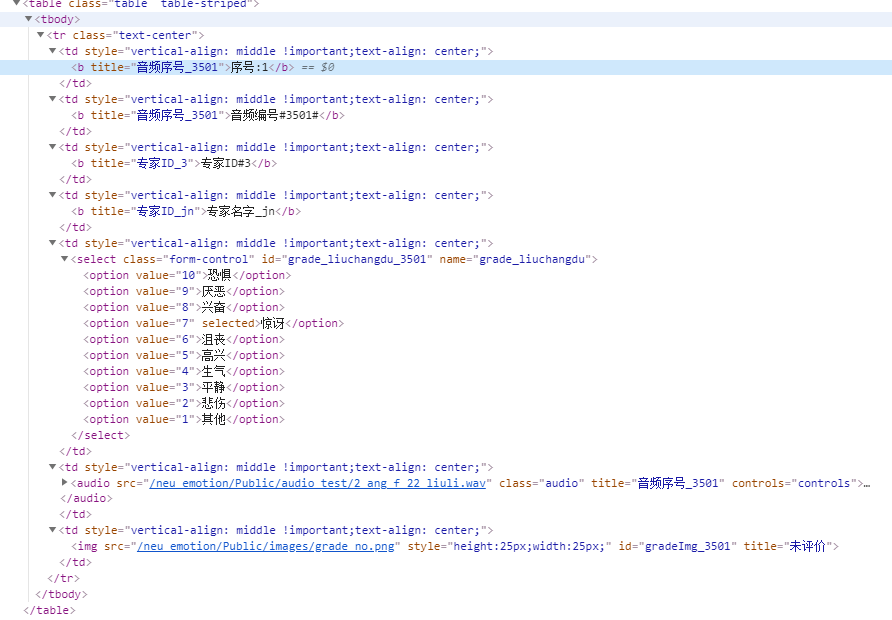
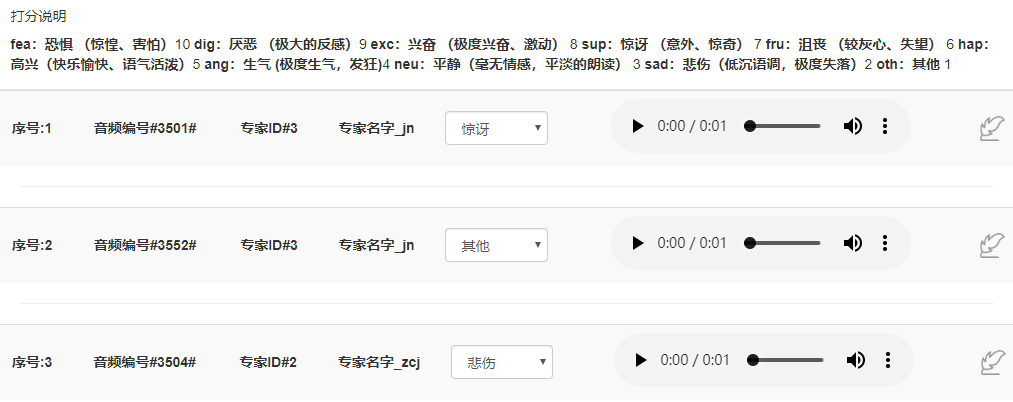
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import pymysql
from scrapy.conf import settings
class GradePipeline(object):
def process_item(self, item, spider):
host = settings['MYSQL_HOST']
user = settings['MYSQL_USER']
psd = settings['MYSQL_PASSWORD']
db = settings['MYSQL_DB']
c = settings['CHARSET']
con = pymysql.connect(host=host, user=user, passwd=psd, db=db, charset=c)
cur = con.cursor()
sql = "INSERT INTO test VALUES(%s,%s,%s,%s,%s,%s)"
item_list = [item['Id'].replace("序号:", ""), item['AudioId'].replace("#", "").replace("音频编号", ""),
item['ExpertId'].replace("专家ID#", ""), item['ExpertName'].replace("专家名字_", ""), item['Feel'],
item['AudioURL']]
cur.execute(sql, item_list)
con.commit()
cur.close()
con.close()
return item
|