import scrapy from urllib.parse import urljoin from scrapy.loader import ItemLoader from douban.items import DoubanItem from scrapy.loader.processors import MapCompose, Join from scrapy.http import Request
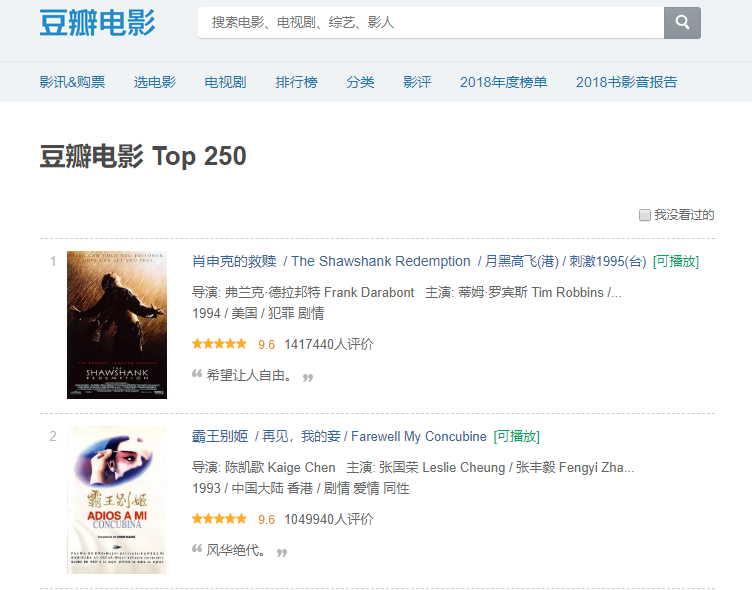
defparse(self, response): next_selector = response.xpath('//span[@class="next"]/a/@href') for url in next_selector.extract(): yield Request(urljoin(response.url, url), dont_filter=True)
item_selector = response.xpath('//div[@class="hd"]/a/@href') for url in item_selector.extract(): yield Request(urljoin(response.url, url), callback=self.parse_item, dont_filter=True)
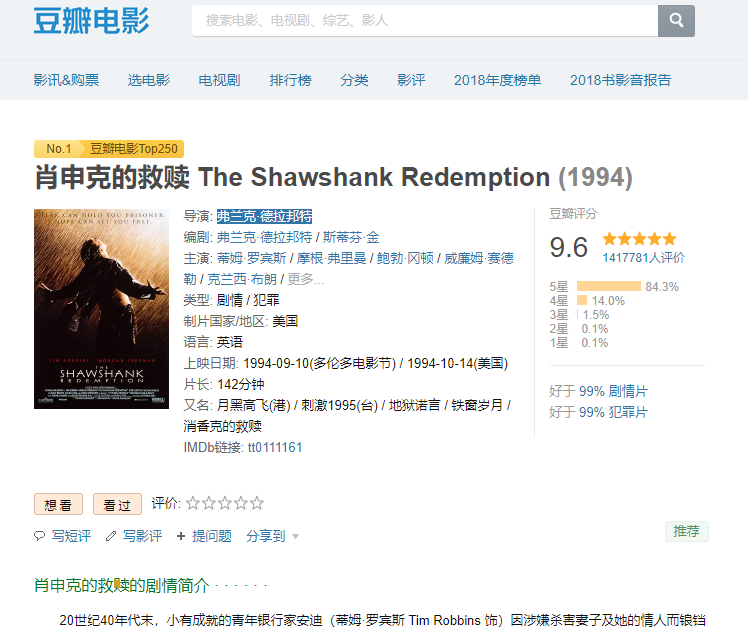
defparse_item(self, response): """ This function parses a property page @url http://movie.douban.com/subject/26683723 @return items 1 @scrapes name average director screenwriter star genre runtime initialReleaseDate summary """
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
# Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'douban (+http://www.yourdomain.com)' USER_AGENT = 'Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0'
# Obey robots.txt rules ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16) CONCURRENT_REQUESTS = 10