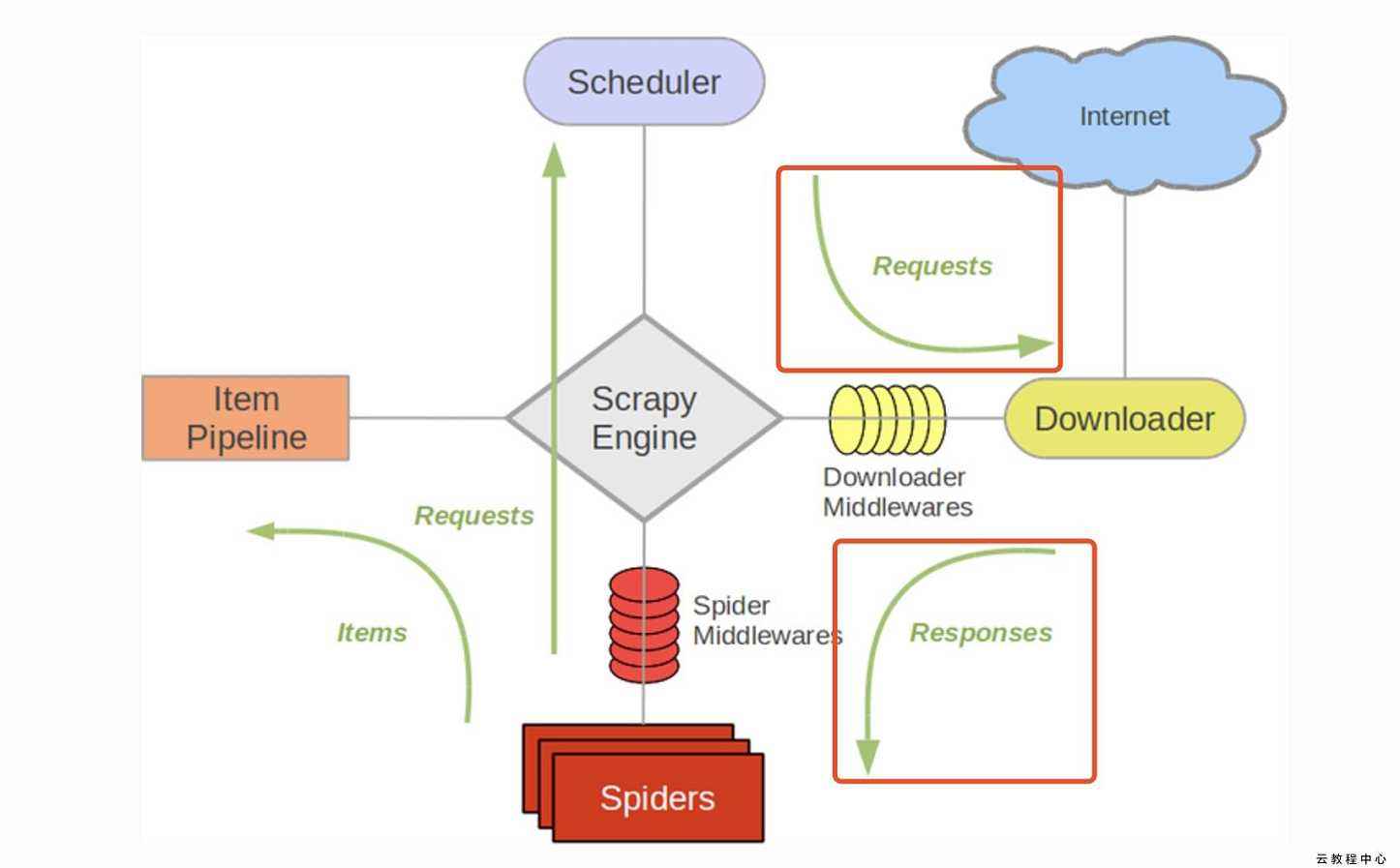
Scrapy豆瓣整站爬虫,爬取豆瓣下电影、读书、音乐、同城四个分类的数据并保存到MySQL,文末有源码
Scrapy豆瓣整站爬虫
分析:
豆瓣的分类有这些

其中读书、电影、音乐、同城的四个分类信息较多、维度较全,我们今天就来爬取这四个分类下的数据
豆瓣电影:
豆瓣电影下的分类导航是最全的,默认选择全部
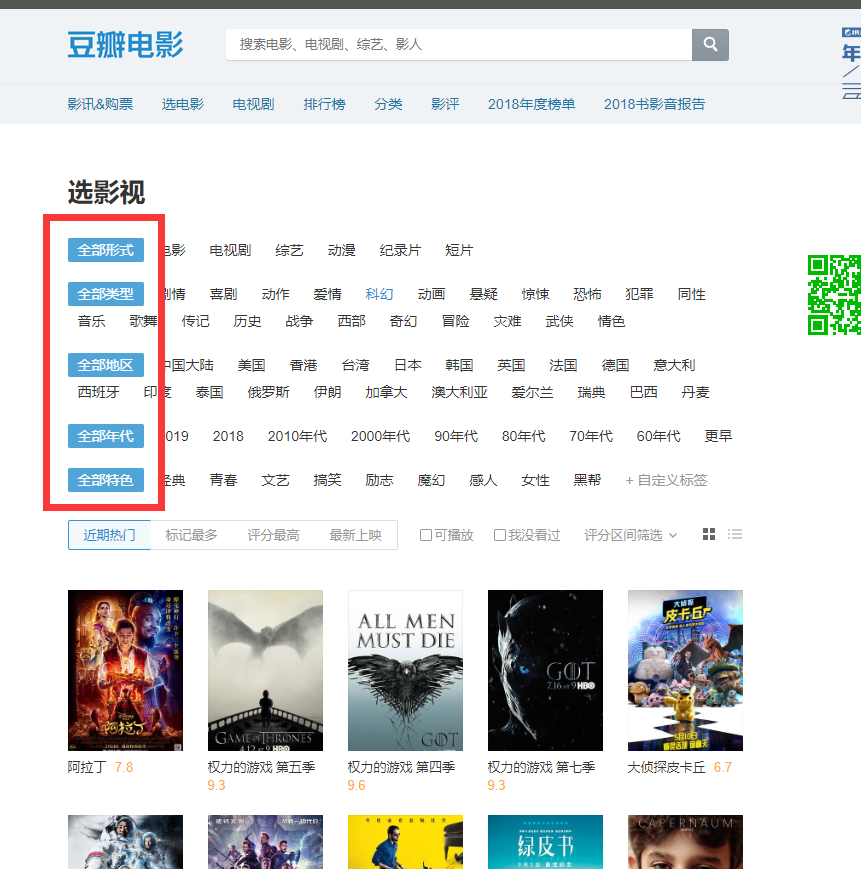
拉到下面点击更多
在F12开发者工具可以看到
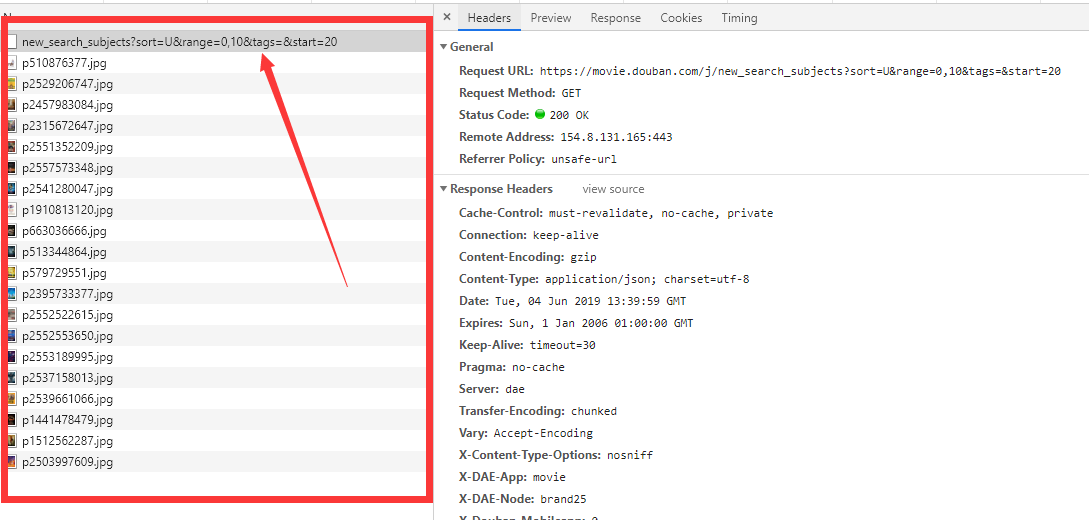
一共出来了21条请求,其中20条是图片,第一条是返回的json数据
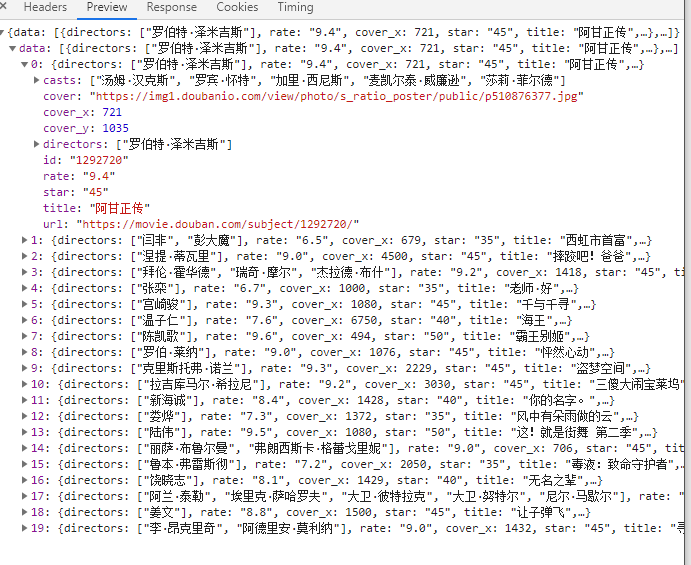
分析这条GET请求
https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=20
range经测试并没有什么用 ,后面的start可以按20的倍数增长
,后面的start可以按20的倍数增长
不过json数据并不是很全,所以需要进每条的详情页也就是
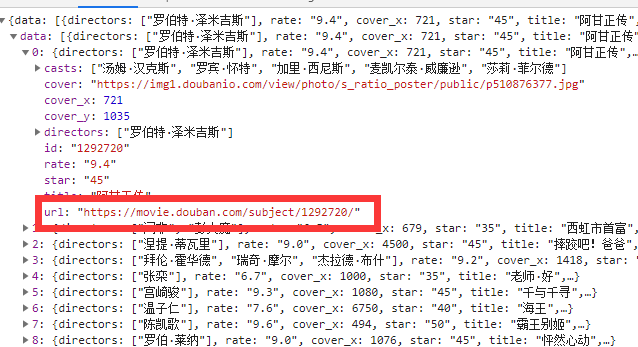
https://movie.douban.com/subject/1292720

在详情页可以采集到比较详细的数据
我们可以这样设计需要采集的数据

经过测试发现有的电影并没有详情页,所以需要将之前的json数据放进去,毕竟也是有点信息的,为了偷懒,我设计爬虫为两次爬取,每次注释一部分代码运行
豆瓣读书:
豆瓣读书按标签可以得到排行(https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4?start=980&type=T)替换标签就可以
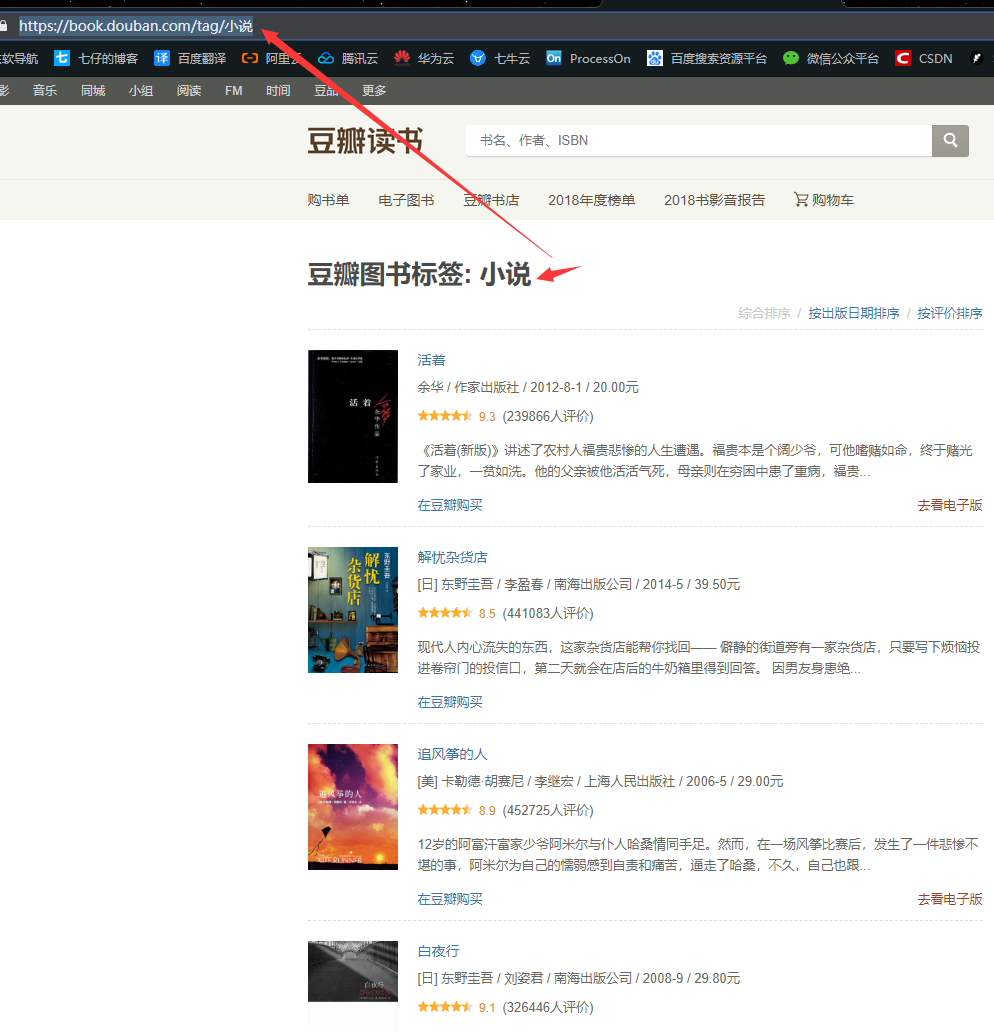
全部标签页为(https://book.douban.com/tag/)
需要注意的是页数显示382页

实际上在页数等于51页(也就是数据量等于1000)的时候,豆瓣就会显示

很迷
操作依据上面电影的双向爬取来就行
需要注意的是详情在html显示是酱紫:
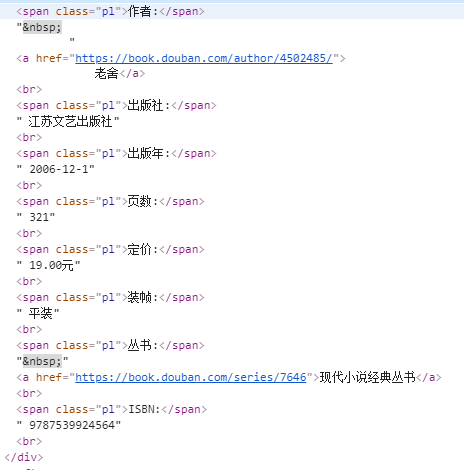
信息不在标签里
我的处理方法是将整个的 “”.join() 放在一个字符串里,然后正则表达式 作者:(.+?)出版社: 就可以提取出来中间的信息
豆瓣音乐和豆瓣同城的分析和上面的差不多,这里就不分析了
代码:
具体的源码我会放在最下面,这里讲解一下怎么将这四个爬虫放在一个项目里
首先是Items.py
1 | # -*- coding: utf-8 -*- |
然后在setting.py中设置
1 | ITEM_PIPELINES = { |
然后每新建一个爬虫,就在spiders目录下 scrapy genspider 爬虫名 web 一个新的爬虫名.py
爬虫中需要添加
1 | custom_settings = { |
来区分
然后运行爬虫时:
1 | scrapy crawl 爬虫名 |
源代码:
此为博主副博客,留言请去主博客,转载请注明出处:https://www.baby7blog.com/myBlog/26.html