1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
| import pymysql
import pandas as pd
from pandas import DataFrame
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
con = pymysql.connect(host='127.0.0.1', user='root', passwd='root', db='python', charset='utf8')
cur = con.cursor()
df = pd.read_sql('SELECT * FROM doubanvideo WHERE '
'genre != "" AND '
'runtime != "" AND '
'average_count != "" '
'AND average != "" AND '
'star_1 != "" AND '
'star_2 != "" AND '
'star_3 != "" AND '
'star_4 != "" AND '
'star_5 != "";', con=con)
con.close()
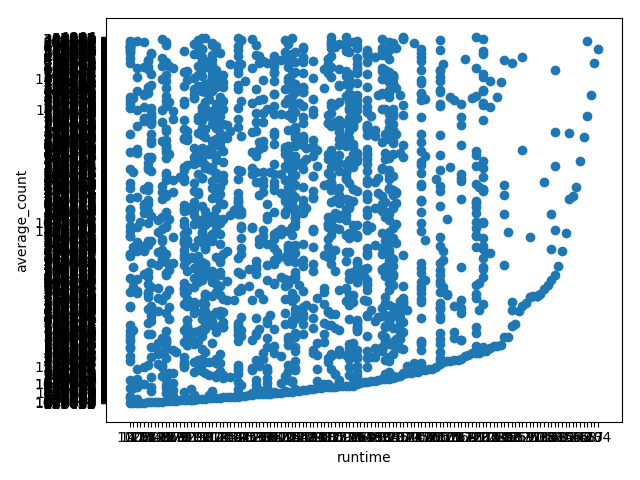
df['runtime'] = df['runtime'].str.replace(r'( *)分钟(.*)', "")
df['runtime'] = df['runtime'].str.replace(r'[a-zA-Z]+:( *)', "")
frame = DataFrame(df)
fig,ax = plt.subplots()
ax.scatter(frame['runtime'], frame['average_count'])
ax.set_xlabel('runtime')
ax.set_ylabel('average_count')
plt.show()
plt.close()
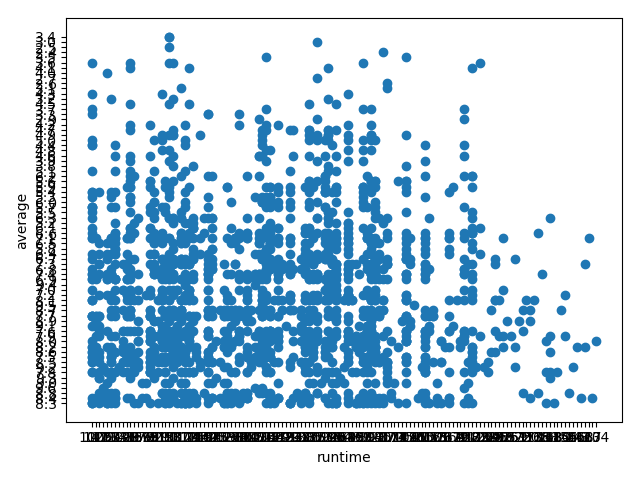
df['runtime'] = df['runtime'].str.replace(r'( *)分钟(.*)', "")
df['runtime'] = df['runtime'].str.replace(r'[a-zA-Z]+:( *)', "")
frame = DataFrame(df)
fig,ax = plt.subplots()
ax.scatter(frame['runtime'], frame['average'])
ax.set_xlabel('runtime')
ax.set_ylabel('average')
plt.show()
plt.close()
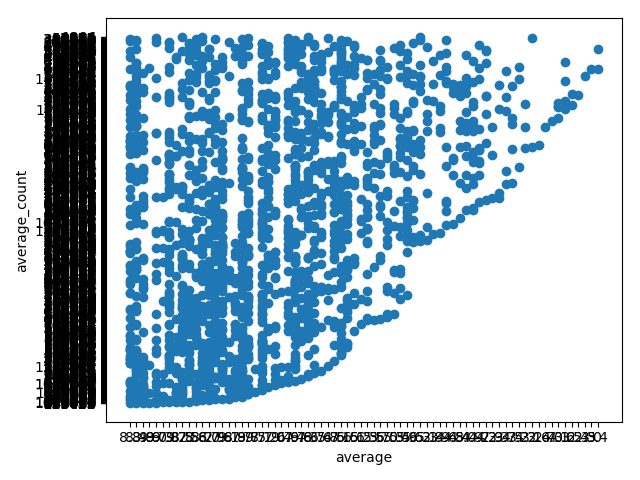
frame = DataFrame(df)
fig,ax = plt.subplots()
ax.scatter(frame['average'], frame['average_count'])
ax.set_xlabel('average')
ax.set_ylabel('average_count')
plt.show()
plt.close()
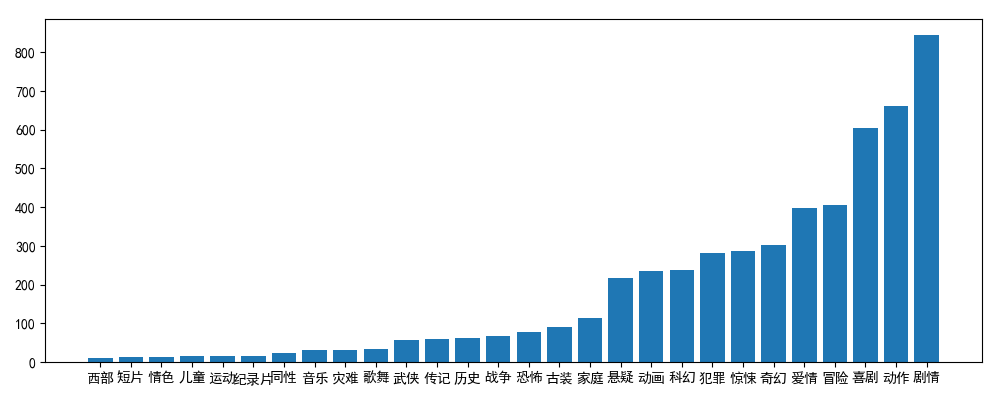
types = {}
frame = DataFrame(df)
for genre in frame['genre']:
strs = genre.split(" ")
for s in strs:
if types.get(s) is None:
types[s] = 1
else:
types[s] += 1
blist = []
clist = []
list = sorted(types.items(), key=lambda item: item[1])
for i in list:
blist.append(i[0])
clist.append(i[1])
plt.rcParams['figure.figsize'] = (10.0, 4.0)
plt.bar(range(len(blist)), clist, tick_label=blist)
plt.show()
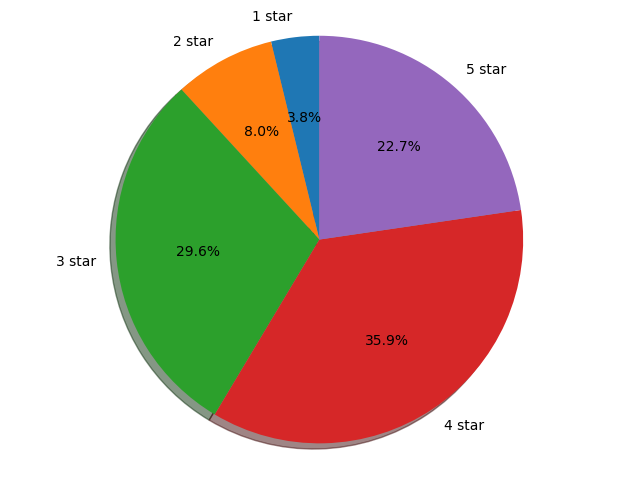
star_1 = DataFrame(df['star_5'].str.replace(r'%', ""), dtype='float').mean()
star_2 = DataFrame(df['star_4'].str.replace(r'%', ""), dtype='float').mean()
star_3 = DataFrame(df['star_3'].str.replace(r'%', ""), dtype='float').mean()
star_4 = DataFrame(df['star_2'].str.replace(r'%', ""), dtype='float').mean()
star_5 = DataFrame(df['star_1'].str.replace(r'%', ""), dtype='float').mean()
labels = '1 star', '2 star', '3 star', '4 star', '5 star'
sizes = [star_1, star_2, star_3, star_4, star_5]
explode = (0, 0, 0, 0, 0)
fig1, ax1 = plt.subplots()
ax1.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%', shadow=True, startangle=90)
ax1.axis('equal')
plt.show()
|