
python自动判断Maven依赖
python自动判断Maven依赖

基于谷歌/火狐无头浏览器模式解决Vue的SEO问题

java.nio.charset.MalformedInputException: Input length = 1

/MySQL相邻去重*/
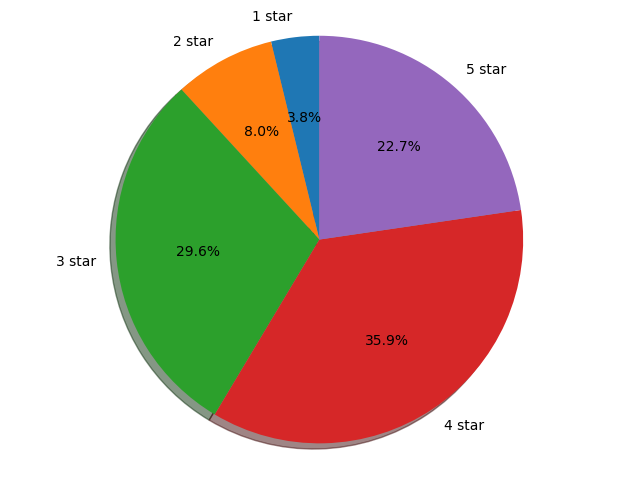
分析了豆瓣电影数据并进行可视化,分析的数据有评论数量、评分、时长、电影类型、评分星级
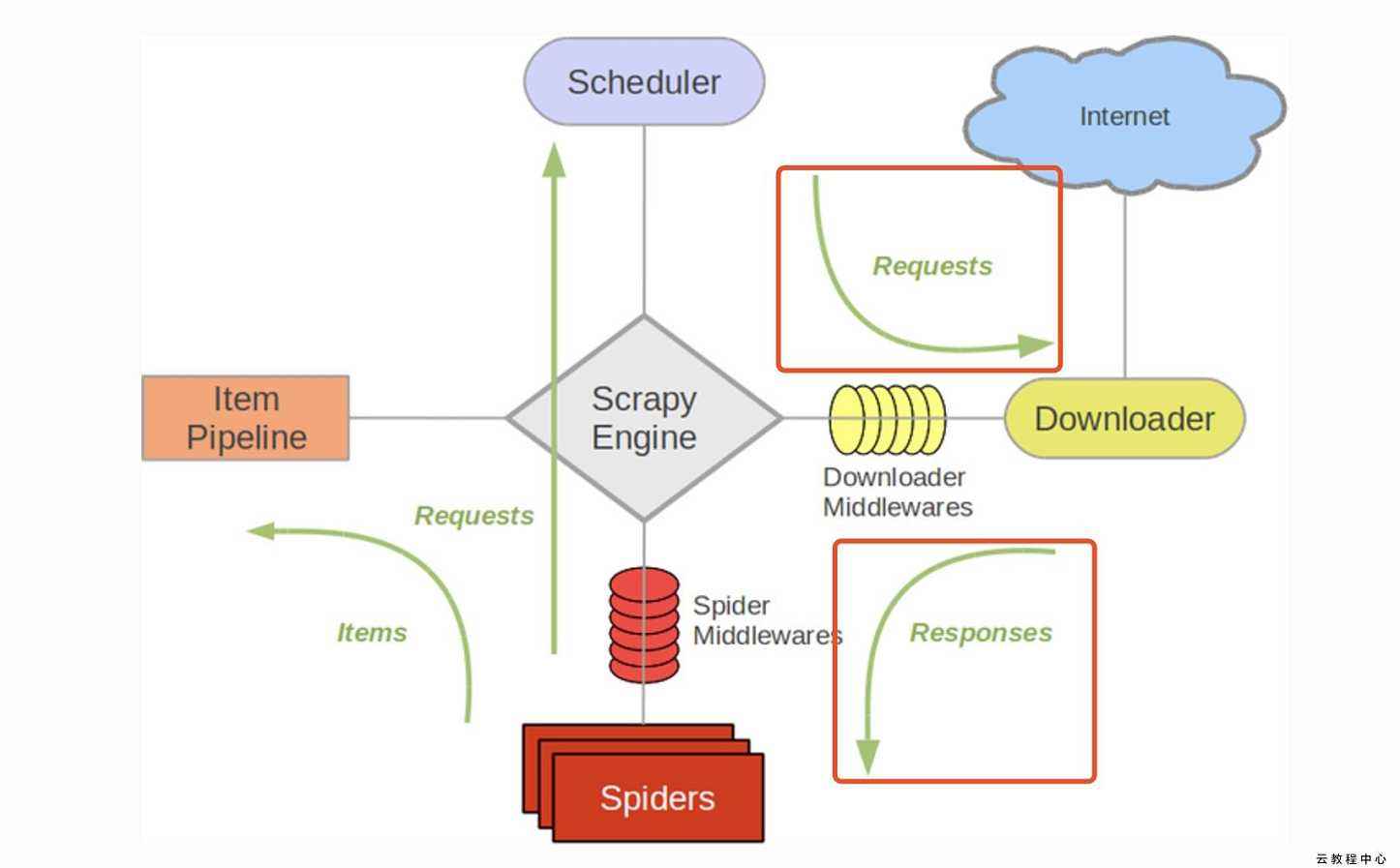
Scrapy豆瓣整站爬虫,爬取豆瓣下电影、读书、音乐、同城四个分类的数据并保存到MySQL,文末有源码
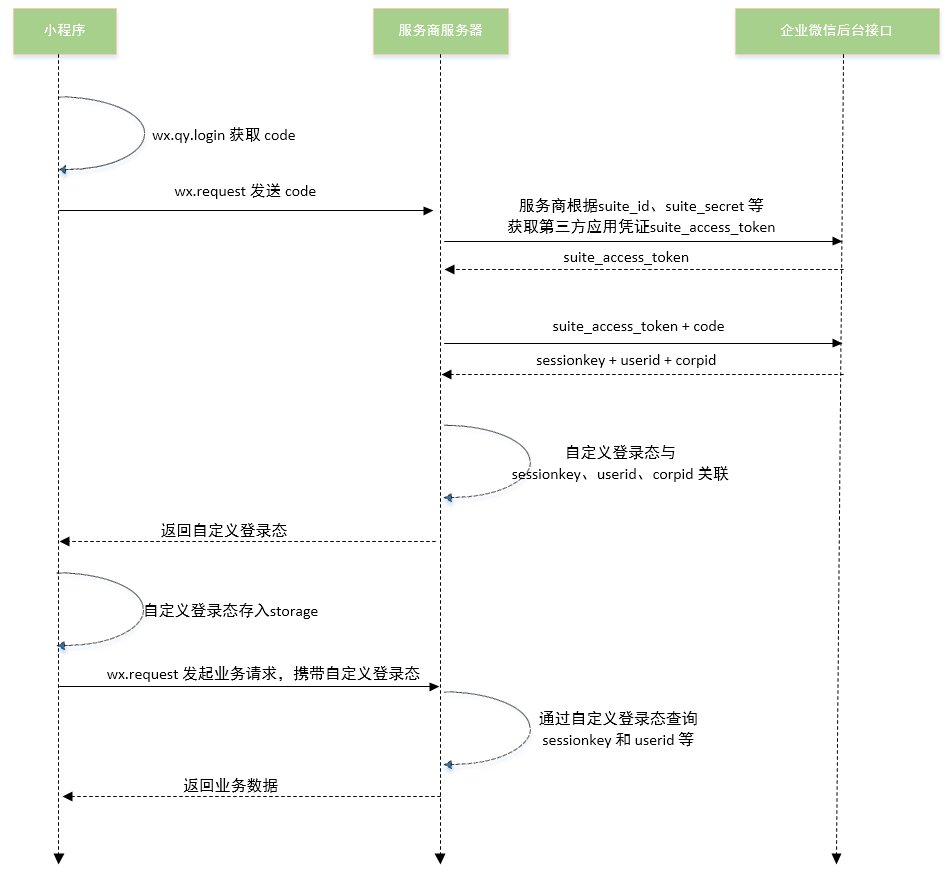
Spring MVC实现微信小程序登录流程
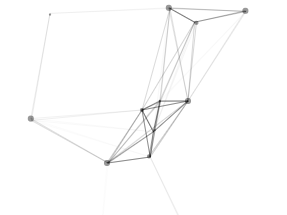
使用JavaScript实现,生成150个点,然后使用嵌套的for循环来判断每两个点之间是否需要连线以及连线的透明度

几个Intellij IDEA插件和快捷操作的分享,后续我如果再遇到好的插件或学习到快捷操作会再更新

MagicMirror²是一个开源的魔镜项目,软件大概原理就是一个Web页面,然后全屏,黑色底色,硬件原理就是在原子镜后面放一个屏幕